[sesac LLM] day31-240215 기계학습(Machine Learning) 기초개념, 의사결정모델
목차
기계학습의 3가지 타입 - 지도학습, 비지도학습, 강화학습
기계학습정의
- 프로그래밍 : 데이터, 알고리즘 -> 컴퓨터 -> 출력결과
- 기계학습 : 데이터, 출력결과 -> 컴퓨터 -> 알고리즘
인공지능 : 컴퓨터가 사람처럼 생각하고 판단하게 만드는 기술
머신러닝 : 인간의 학습능력과 같은 기능을 컴퓨터에 부여하기 위한 기술
딥러닝 : 인공지능 신경망을 기반으로 한 머신러닝 방법론 중 하나
기계학습 (Machine Learning 머신러닝)의 3가지 타입
- 지도학습 (Supervised Learning)
- 레이블이 지정된 데이터를 사용하여 학습
- 미래 데이터 예측
- 예시: 회귀 (Regression), 분류 (Classification)
- 비지도학습 (Unsupervised Learning)
- 레이블이 없는 데이터를 사용하여 패턴이나 구조 발견
- 예시: 클러스터링 (Clustering), 차원축소, 연관규칙
- 비지도학습은 정답이 없는 데이터를 가지고 모델이 스스로 학습하는 방법이다. 예를 들어, 성별에 대한 레이블 없이 사람들의 데이터만 주어진 경우, 비지도학습 알고리즘은 데이터 포인트들 사이의 패턴이나 관계를 찾아내야 한다.
- 강화학습 (Reinforcement Learning)
- 보상 시스템을 통해 시행착오를 통한 학습
- 의사결정을 위한 최적의 행동 전략을 학습
회귀와 분류
1) 회귀
회귀는 연속적인 데이터를 다루며, 샘플마다 특정 값을 정확히 예측해야 한다. 예를 들어 재고량, 판매량, 강수량, 기온, 광고 클릭률 등이 연속적인 수치 데이터의 예시다. 회귀 모델은 이러한 연속적인 실수 값을 예측하는 데 사용된다.
2) 분류
분류는 범주형 데이터를 다루는데, 예를 들어 꽃잎 데이터를 세 가지 종류로 분류하는 것이다. 이는 정답 레이블이 명확한 범주(예: 꽃의 종류)에 속한다.
클러스터링
클러스터링은 비지도학습에서 데이터의 유사성을 기준으로 그룹화하는 방법이다. 데이터를 수치적인 벡터 형태로 변환하고, 이 벡터들 간의 거리를 계산하여 유사한 데이터끼리 클러스터로 묶는다. 이 과정을 통해 데이터 내 숨겨진 구조를 찾아낼 수 있다.
머신러닝의 전체과정
머신러닝 파이프라인
[RAW DATA-> DATA PROCESS-> FEATURE ENGINERING-> FEATURE SCALING->FEATURE SELECTION]
=> [MODELING(MACHINE LEARNING ALGORITHM]=>[EVALUATION]=>[SUBMIT OR DEPLOY]
머신러닝 (지도학습)의 전체 과정
머신러닝(지도학습)의 전체과정은 크게 데이터 준비, 모델 선택, 학습, 예측, 그리고 평가의 단계로 이루어진다. 데이터 준비 단계에서는 문제에 적합한 데이터를 수집하고 처리한다. 모델 선택 단계에서는 문제 해결에 적합한 알고리즘을 고른다. 학습 단계에서는 데이터를 모델에 주입하여 패턴을 인식하도록 한다. 예측 단계에서는 학습된 모델을 사용해 새로운 데이터에 대한 결과를 예측한다. 마지막으로 평가 단계에서는 예측 성능을 검증하고 필요하다면 모델을 조정한다.
- 데이터 준비: 문제에 적합한 데이터를 수집하고 처리
- 모델 선택: 문제 해결에 적합한 알고리즘 선택
- 학습: 데이터를 모델에 주입하여 패턴 인식
- 예측: 학습된 모델을 사용해 새로운 데이터에 대한 결과 예측
- 평가: 예측 성능을 검증하고 모델을 조정
비유
머신러닝 과정을 학생의 기출문제 학습에 비유하면 다음과 같다. 먼저 학생이 문제집(X_train)과 답안(y_train)을 준비하는 것처럼, 데이터와 레이블을 준비한다. 그다음, 문제를 풀며 공부하는 것처럼 모델이 학습 데이터로부터 패턴을 학습한다. 시험에서 새 문제(X_test)를 푸는 것처럼 모델이 새 데이터에 대한 예측(y_pred)을 한다. 마지막으로, 시험 답안을 채점하듯, 예측 성능을 실제 값(y_test)과 비교해 평가한다. 필요하면 모델을 조정하여 성능을 향상시킨다.
1) X_train(문제집), y_train(답안) 데이터를 ----모델에 넣어준다----> Model
2) 모델이 학습한다.
3) X_test(새문제)를 바탕으로 y_pred를 예측한다.
4) y_test(새문제 답안)으로 평가한다.
5) 모델을 저장하여 성능을 향상시킨다.
학습과 예측 전체 과정 비유
feature_names : 학습(훈련), 예측에 사용할 컬럼을 리스트 형태로 만들어서 변수에 담아줍니다.
label_name : 정답값
X_train : feature_names 에 해당되는 컬럼만 train에서 가져옵니다.
학습(훈련)에 사용할 데이터셋 예) 시험의 기출문제
X_test : feature_names 에 해당되는 컬럼만 test에서 가져옵니다.
예측에 사용할 데이터셋 예) 실전 시험문제
y_train : label_name 에 해당 되는 컬럼만 train에서 가져옵니다.
학습(훈련)에 사용할 정답 값 예) 기출문제의 정답
model : 학습, 예측에 사용할 머신러닝 알고리즘
model.fit(X_train, y_train) : 학습(훈련), 기출문제와 정답을 가지고 학습(훈련)하는 과정과 유사합니다.
model.predict(X_test) : 예측, 실제 시험을 보는 과정과 유사합니다. => 문제를 풀어서 정답을 구합니다.
score
시험을 봤다면 몇 문제를 맞고 틀렸는지 채점해 봅니다.
metric
점수를 채점하는 공식입니다. (예를 들어 학교에서 중간고사를 봤다면 전체 평균을 계산해 줍니다.)머신러닝의 종류
1. 지도학습(Supervised learning)
1-1. 분류(Classification)
Decision Tree (의사결정나무)
Logistic Regression (로지스틱 회귀)
Naive Bayes (나이브 베이즈)
KNN (K-Nearest Neighbor, K-최근접이웃)
Random Forest (트리 기반)
SVM (Support Vector Machine, 서포트 벡터 머신)
XGBoost (트리 기반)
LightGBM (트리 기반)
회귀(Regression)
1-2. Decision Tree (의사결정나무)
Linear Regression (선형 회귀)
Regularized Linear Regression (규제 선형 회귀)
Regression Tree (회귀 트리)
KNN (K-Nearest Neighbor, K-최근접이웃)
Random Forest (트리 기반)
SVM (Support Vector Machine, 서포트 벡터 머신)
XGBoost (트리 기반)
LightGBM (트리 기반)
2. 비지도학습(Unsupervised learning)
2-1. 차원 축소(Dimensionality Reduction)
PCA (주성분 분석)
Factor Analysis (요인 분석)
MDS (다차원 척도법)
군집화(Clustering)
2-2.Hierarchical Clustering (계층적 군집화)
K-means Clustering (K-평균 군집화)
K-medoids Clustering
SOM (자기조직화지도)
2-3. 연관 규칙(Association Rules)
MBA (장바구니 분석)
Sequence MBA (순차장바구니)
Collaborative Filtering (협업 필터링, 추천 시스템)머신러닝실습- 결정트리분류기(DecisionTreeClassifier)
결정트리분류기 (DecisionTreeClassifier)
- 데이터 불러오기 및 살펴보기
- 데이터셋 출처: Pima Indians Diabetes Database | Kaggle
- 주요 컬럼: Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI, DiabetesPedigreeFunction, Age, Outcome
- 학습, 예측 데이터셋 나누기
- 8:2 비율로 데이터 나누기
- train과 test 데이터셋 생성
- 학습 및 예측 데이터셋 만들기
- X_train, y_train, X_test, y_test 생성
- 결정 트리 모델 학습
- DecisionTreeClassifier 사용
- 모델 학습: model.fit(X_train, y_train)
- 예측 및 시각화
- 예측: model.predict(X_test)
- 시각화: plot_tree, sns.barplot
- 평가
- 정확도: (y_test == y_pred).mean() * 100
- 피처 중요도: model.feature_importances_
당뇨병 여부 분류를 해볼 것이다.
01_pima_classification_baseline
1. 데이터를 불러오고 데이터를 살펴보자.
데이터셋 출처 :Pima Indians Diabetes Database | Kaggle
1) 데이터 구성 :
정답 레이블을 outcoome (0,1) 으로 두고, 이것이 범주형이기 때문에-> 분류모델이다.
Pregnancies : 임신 횟수
Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
BloodPressure : 이완기 혈압 (mm Hg)
SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
Insulin : 2시간 혈청 인슐린 (mu U / ml)
BMI : 체질량 지수 (체중kg / 키(m)^2)
DiabetesPedigreeFunction : 당뇨병 혈통 기능
Age : 나이
Outcome : 당뇨병 여부, 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
0 : 당뇨병 없음
1 : 당뇨병 있음2) 필요한 라이브러리 로드한다.
# 데이터 분석을 위한 pandas, 수치계산을 위한 numpy
# 시각화를 위한 seaborn, matplotlib.pyplot 을 로드합니다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt3) 데이터셋을 로드한다.
df = pd.read_csv("/content/drive/MyDrive/diabetes.csv")
#이 과정에서 마운트 필요df.shape을 통해 행,열의 개수를 확인한다.
df.sample(3) 을 통해 3개의 행을 확인한다.
df.info()를 통해 데이터프레임에 대한 주요 정보를 확인한다.(인덱스 범위, column, non-null 값의 개수, 컬럼별 dtype, memory usage)
_ = df.hist(figsize=(10, 8), bins=100)를 통해 수치형 컬럼의 히스토그램을 확인한다. 데이터 분포를 시각적으로 확인할 수 있다. figsize 10,8은 너비와 높이를 나타낸다.
2. 학습, 예측 데이터셋 나누기
1) train과 test 데이터셋을 8:2 의 비율로 구하기 위해 전체 데이터의 행에서 80% 위치에 해당되는 값을 구해서 split_count 라는 변수에 담는다.
전체에서 8:2, 7:3의 비율로 보통 훈련데이터와 테스트 데이터를 나누는데, 모델이 다양한 패턴과 특징을 학습할 수 있도록 하기 위함이다. 그렇다고 테스트 데이터가 너무 적으면 안되니까 8:2, 7:3을 많이 사용한다.
#행의 개수 구하기
df.shape[0]
#df.shape[0]은 행의 개수이고, df.shape[1]은 컬럼의 개수를 나타낸다.
#결과 : 768train, test를 슬라이싱을 통해 데이터를 나눈다.
#전체 행의 개수에 0.8을 곱해서 split_count 변수안에 할당한다.
split_count = int(df.shape[0] * 0.8)
split_count# 전체 데이터프레임의 80%에 해당하는 행을 훈련 데이터로 선택
train = df[:split_count] # 80%
train.shape
#훈련 데이터셋의 형태(행의 개수와 열의 개수)를 출력# 전체 데이터프레임의 80%에 해당하는 행을 훈련 데이터로 선택
test = df[split_count:] #20%
test.shapetrain과 test를 80:20으로 나누었을때 , 그 둘의 행의 합이 전체 행의 개수와 같아야한다.
train.shape[0] + test.shape[0] == df.shape[0]True가 나오는 것을 확인.
3.학습, 예측 데이터셋 만들기
1) 학습과 예측컬럼을 나누기 위해, 전체 컬럼에서 정답 컬럼을 제거한다.
# label_name 이라는 변수에 예측할 컬럼의 이름을 담는다.
label_name = "Outcome"label_name을 remove하여 feature_names에 정답칼럼을 제거해준다.
# 학습 세트 만들기 예) 시험의 기출문제
feature_names = df.columns.tolist() #데이터프레임의 컬럼이름을 리스트로 변환한다.
feature_names.remove(label_name) #remove 메서드를 사용해 특성 리스트에서 타겟변수를 제거한다.
feature_names2) X_train 훈련데이터셋 생성
# 훈련데이터 만들기 예) 시험의 기출문제
X_train = train[feature_names]
print(X_train.shape)
X_train.head()3) y_train 훈련데이터셋의 레이블 생성
# 정답 값을 만들어 줍니다. 예) 기출문제의 정답
y_train = train[label_name]
y_train4) X_test 테스트 데이터셋 생성
# 예측에 사용할 데이터세트를 만듭니다. 예) 실전 시험 문제
X_test = test[feature_names]
print(X_test.shape)
X_test.head()5) y_test 테스트 데이터셋의 레이블 생성
# 예측의 정답값 예) 실전 시험 문제의 정답
y_test = test[label_name]
y_test이렇게 정리해볼 수 있겠다.

4. 머신러닝 알고리즘 실습
결정트리를 실습해보도록한다. 결정트리는 사이킷런 라이브러리에서 제공하는 결정 트리 분류 모델 클래스이다. 자세한 설명은 위키백과에서 확인
결정트리 특징
- 결과 해석 용이: 복잡한 설명 없이도 모델의 결과를 쉽게 이해할 수 있다.(화이트박스)
- 데이터 전처리 최소화: 정규화나 누락된 값 처리 없이 원본 데이터를 사용할 수 있다.
- 다양한 데이터 유형 적용: 수치형과 범주형 변수를 모두 처리할 수 있다.
주요 파라미터
주요 파라미터criterion: 가지의 분할의 품질을 측정하는 기능.
max_depth: 트리의 최대 깊이
min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수
min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수
max_leaf_nodes: 리프 노드 숫자의 제한치
random_state: 추정기의 무작위성을 제어합니다.실행했을 때 같은 결과가 나오도록 함.
1) 결정 트리 분류 모델 생성
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth = None,
max_features= 0.9, # 전체 feature의 90%만 사용
random_state=42)사이킷런의 DecisionTreeClassifier를 사용하여 결정 트리 분류 모델을 구성하는 방식이다. 위의 코드를 보면
max_depth=None을 주어 트리의 최대 깊이를 제한하지 않았고, 데이터에 완벽하게 맞춰질 때까지 분기할 수 있다는 의미다. ( 분기는 결정 트리에서 데이터를 나누는 결정 지점을 말한다. 각 분기는 트리의 노드가 되며, 결정 트리의 학습 과정에서 중요한 역할을 한다.)
max_features=0.9는 전체 feature의 90%만 사용하겠다는 뜻이다. 100개의 특성이 있으면 무작위로 선택된 90개의 특성만을 고려한다.
random_state=42는 재현할때마다 동일한 결과(동일한 난수패턴)가 나오게끔 하기 위해서 쓰는 것이다. 여러번 실행해도 동일한 방식으로 데이터를 분할하고 같은 트리를 생성할 수 있도록 한다. 꼭 42일 필요는 없고 어떤 숫자를 써줘도 상관없다.

2) 결정 트리 분류 모델로 학습(훈련)
model.fit(X_train, y_train).fit()은 사이킷런 라이브러리에서 제공하는 머신러닝 모델을 훈련시키는 메소드이다. model.fit()으로 생성한 모델을 훈련시킨다.
X_train: 모델이 패턴을 학습할 수 있도록 특성 데이터를 제공
y_train : 훈련 데이터에 대한 정답 레이블 제공
이 두 인수를 model.fit()에 제공함으로써, 모델은 X_train에서 제공하는 특성에 기반하여 y_train의 레이블을 정확히 예측하도록 내부 파라미터를 조정하고 최적화하는 학습을 수행한다. 이 학습 과정을 통해 모델은 주어진 데이터의 패턴을 이해하고, 나중에 새로운 데이터에 대한 정확한 예측을 수행할 수 있다.
3) 예측
y_pred = model.predict(X_test)
y_pred[:10].pred()는 훈련된 모델(model)을 사용하여 입력 데이터(X_test)에 대한 예측을 수행한다. y_pred[:10]로 첫 10개의 결과를 빠르게 확인할 수 있다.
4) 의사결정나무를 시각화
# plot_tree 를 통해 시각화 합니다.
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 20))
plot_tree(model, fontsize=10, feature_names = feature_names, filled=True)
plt.show()figsize 는 그림의 크기, fontsize는 트리 내 텍스트 크기, filled=True는 노드의 클래스에 따라 색을 다르게 채워 시각적으로 구분이 쉽도록 한다.

5) 피처의 중요도 추출
# 피처의 중요도를 추출하기
np.sum(model.feature_importances_)
#코드 결과
1.0model.feature_importances_는 사이킷런에서 제공하는 결정 트리 기반의 모델(예: 결정 트리, 랜덤 포레스트 등)에서 각 특성(변수)의 중요도를 나타내는 속성이다.
np.sum( ) 은 중요도 배열의 합을 계산한다. 결정 트리 모델에서는 모든 특성의 중요도를 합하면 1이 되어야한다. 이 코드의 결과는 일반적으로 1이 나온다.
6) 피처의 중요도 시각화
# 피처의 중요도 시각화 하기
sns.barplot(x= model.feature_importances_, y=feature_names, hue=feature_names)
7) 정확도 추출
모델이 얼마나 잘 예측했나 확인하는 코드이다.
# 예측의 정확도 구하는 방법. 100점 만점 중에 몇 점을 맞았는지 확인한다.
(y_test == y_pred).mean()* 100
#혹은 이렇게 정확도를 구한다.
#미리 구현된 알고리즘으로 확인하는 방법이다.
accuracy_score(y_test, y_pred) * 100
# model 의 score 로 점수를 계산할 수도 있다.
model.score(X_test, y_test) * 100세 방법 모두
72.07792207792207로 결과가 나온다.
의사결정트리 이론
- 분류와 회귀 모두 가능한 지도학습 모델 중 하나이다.
- 스무고개 하듯이 예 아니오 질문을 이어가면서 학습한다.
- 최상단 질문은 루트 노드라고 하며, 가운데 노드는 중간마디, 규칙노드라고 한다. 최하단은 리프(leaf)노드, 터미널 노드라고 한다.
한번 분기할 때마다 변수 영역을 두개로 구분한는데 순도가 증가하고 불순도가 최대한 감소하는 방향으로 학습을 진행한다. 불순도는 해당 범주 안에서 서로 다른 데이터가 얼마나 섞여있는지를 뜻한다. 이 불순도가 감소하는걸 정보획득이라고 한다.
1) 순도를 계산하는 3가지 방식
- 엔트로피, 지니계수, 오분류오차
엔트로피 : 엔트로피가 높다면 불순도가 높고, 낮으면 불순도가 낮다. 불순도가 1이면 불순도가 최대이고 한 범주안에 서로 다른 데이터가 정확히 반반있다는 뜻이다.
지니계수 : 지니계수가 0.5에 가까울수록 불순도가 최대이다.
오분류오차 : 사이킷런에는 없다.
2) 디시전트리모델 과정
모델은 최적의 특성을 선택해 데이터를 분할하고, 이를 반복해 각 노드의 순도가 증가하도록 트리를 구축한다.
3) 오버피팅 막는 전략
디시전트리는 오버피팅이 잘된다.
그래서 과대적합을 막는 전략을 세워야한다.
사전 가지치기 - 트리 생성을 일찍 중단하는 전략이다. 트리의 max_depth 나 리프의 최대개수를 제한한다. 노드가 분할하기 위한 포인트 최소개수를 지정한다.
EDA실습
1) 라이브러리 import
# 데이터 분석을 위한 pandas, 수치계산을 위한 numpy
# 시각화를 위한 seaborn, matplotlib.pyplot 을 로드합니다.
import pandas as pd # 데이터 분석을 위한 pandas
import numpy as np # 수치계산을 위한 numpy
import seaborn as sns # 시각화
import matplotlib.pyplot as plt # 시각화2) 데이터셋 로드
df = pd.read_csv("경로/파일이름.csv")
df.shapeshape로 행과 열의 개수를 확인할 수 있다.
3) 열 빈도수, 비율 확인
df['Outcome'].value_counts()0 500
1 268
Name: Outcome, dtype: int64# 'Outcome' 열에서 차지하는 비율을 계산
df['Outcome'].value_counts(normalize=True)0 0.651042
1 0.348958
Name: Outcome, dtype: float644) 수치형 변수를 histogram으로 수치화
_ = df.hist(bins=50, figsize=(12, 10))
plt.show()bins는 히스토그램의 막대 개수를 지정하고, figsize는 매개변수 플롯의 크기를 지정한다. 가로 12인치, 세로 10인치이다.
plt.show()는 그려진 플롯을 화면에 표시하는 역할을 한다.

5) countplot()을 활용하여 Pregnancies 에 따른 outcome count하여 분포 확인하기
# sns.countplot(data = 데이터 , x= x 축에 해당하는 데이터, hue = 색상을 구분하는 변수)
sns.countplot(data=df, x="Pregnancies", hue="Outcome")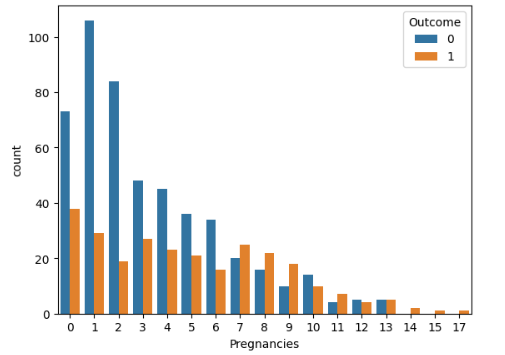
6) violinplot을 사용해 분포 확인
sns.violinplot(data=df)데이터 분포를 바이올린 그래프로 확인할 수 있다.

안에 있는 검정색 박스는 박스플롯이다.
하얀색은 중앙값이다.
옆으로 뚱뚱한 것이 데이터 분포 밀도가 높은 것이다.
Feature Engineering
Feature Engineering은 기계 학습 모델의 성능을 향상시키기 위해 원시 데이터에서 유용한 특성(features)을 생성, 선택, 변환하는 과정이다. 데이터의 정보를 최대한 활용하여 모델이 학습할 수 있는 형태로 데이터를 조작하고 개선하는 것을 목표로 한다.
7) 수치형 변수로 범주형 파생변수 만들기
임신횟수가 6회 이상인 변수를 pregancies_high라고 설정
# Pregnancies_high 파생변수 만들기
# 임신횟수가 6보다 큰 값의 True, False 값을 파생변수로 만들기
df["Pregnancies_high"] = df['Pregnancies'] > 6pregancies_high 에 False, True 로 값이 담긴다.
8) 결측치 다루기
8-1) 결측치 수와 비율을 알아보자.
#결측치 수
df["Insulin_nan"].isnull().sum()
#결측치 비율
df["Insulin_nan"].isnull().mean()8-2) 당뇨병 여부에 따라 평균, 중앙값 구하기
in_desc = df.groupby("Outcome")["Insulin_nan"].describe()
in_desc# 당뇨병이 아닐 때 중앙값
in_desc.loc[0, "50%"]in_desc.loc[1, "50%"]8-3) 결측치에 중앙값으로 채우기
# 결측치 채우기
df["Insulin_filled"] = df["Insulin_nan"]
df.loc[df["Insulin_nan"].isnull() & (df["Outcome"]==0), "Insulin_filled"] = in_desc.loc[0, "50%"]
df.loc[df["Insulin_nan"].isnull() & (df["Outcome"]==1), "Insulin_filled"] = in_desc.loc[1, "50%"]df["Insulin_filled"].isnull().sum()를 통해 결측치가 다 제거되었는지 확인한다. 0 이 되면 된다.
평균, 최빈값, 0으로 넣는 방법, dropna로 제거하는 방법도 있다.
9) 이상치 다루기
plt.figure(figsize=(10, 10))
sns.boxplot(df["Insulin_filled"])
df["Insulin_filled"].describe()
'Insulin_filled' 컬럼의 기술 통계를 계산한다.
# 이상치 찾기
df.loc[ df["Insulin_filled"]> 400, "Insulin_filled"] = 400'Insulin_filled' 컬럼에서 400보다 큰 값을 모두 400으로 설정한다.
# Kernel Density Estimate, KDE --> PDF
sns.kdeplot(df["Insulin_filled"])이상치를 제한한 후의 데이터 분포를 확인할 수 있다.
머신러닝실습- 결정트리회귀기(DecisionTreeRegressor)
데이터셋
0) 전처리 과정
#정답이자 예측해야할 값
label_name = "belly"
label_name#학습과 예측에 사용될 컬럼
['case',
'site',
'age',
'hdlngth',
'skullw',
'totlngth',
'taill',
'footlgth',
'earconch',
'eye',
'chest']나머지 전처리과정은 위와 거의 동일 , pass
1) 학습
회귀모델이기 때문에 Classfier가 아닌 DecisionTreeRegressor를 써야한다.
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(random_state=42)
model모델생성
model.fit(X_train, y_train)모델 학습
2) cross validation 으로 학습 세트의 오차 측정하기
# model_selection의 cross_val_predict 로 cv 로 조각을 나눠 valid 데이터의 학습결과 측정하기
from sklearn.model_selection import cross_val_predict
y_valid_predict = cross_val_predict(model, X_train, y_train, cv=5, n_jobs=-1, verbose=2)
y_valid_predict[:10]cv 는 cross validation을 의미한다. 크로스델리베이션으로 학습세트 오차를 측정할 수 있다. 사이킷런 안에 있는 모델 셀렉션 안에 있는 cross_val_predict을 import 해준다.
cv=5는 전체데이터에서 훈련데이터를 기준으로 다섯개의 집단으로 나눈 형태이다. 데이터를 5개의 조각으로 나눠 각 조각을 한 번씩 검증 데이터로 사용하며 교차 검증을 수행한다는 뜻이다.
왜 검증데이터 validation data가 필요하나. => 과대적합이 될 수 있기 때문에
검증데이터는 과대적합을 방지하기 위해서 훈련도중에 중간중간에 검증하는 용도로 쓰인다.
validation data도 train data에서 8:2의 비율로 만들어준다.
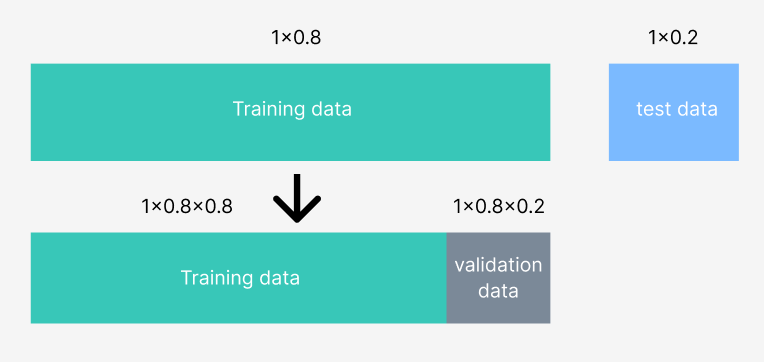
이 validation data를 어떻게 구성하냐면 training data를 5개의 군집으로 나눈다. 각각의 군집을 fold라고 한다.
하나의 fold를 validation set으로 두고 나머지 fold들의 과적합 여부를 판단한다. 다섯개의 군집으로 나눴으니 다섯번 해준다.

결국 cross validation은 집단을 바꿔가면서 데이터가 한쪽에만 오버피팅 났는지 아니면 다른쪽은 오버피팅 안났는지 확인하는것이다. cv = 5 는 집단을 다섯 집단으로 나눴다는걸로 이해하면된다.
n_jobs = -1는 cpu에 돌릴거냐를 물어보는거고 verbose는 progress 바를 보여줄것인지 아닌지를 설정하는 것이다.
더보기
n_jobs와 verbose는 scikit-learn에서 모델 학습 및 교차 검증을 수행할 때 사용할 수 있는 옵션들이다. 각 옵션의 의미와 사용법은 다음과 같다:
n_jobs
- 의미: n_jobs는 사용할 CPU 코어의 수를 지정한다. 이 옵션을 설정함으로써 병렬 처리를 활용해 계산을 더 빠르게 수행할 수 있다.
- 사용법:
- n_jobs=-1: 모든 사용 가능한 CPU 코어를 사용한다.
- n_jobs=1: 병렬 처리 없이 단일 코어만 사용한다.
- n_jobs=k: k개의 CPU 코어를 사용한다. 여기서 k는 사용자가 지정한 양의 정수다.
verbose
- 의미: verbose는 함수의 실행 동안 출력할 정보의 양을 결정한다. 이 옵션을 통해 사용자는 실행 과정에서 발생하는 내부 메시지의 상세한 정도를 조절할 수 있다.
- 사용법:
- verbose=0: 학습 진행 과정을 전혀 보여주지 않는다(조용).
- verbose=1: 학습 진행 과정에서 애니메이션 진행 바를 보여준다.
- verbose=2: 학습의 각 에포크를 한 줄로 간단히 보여준다.
3) 위 과정을 기반으로 정답을 맞췄는지 안맞췄는지 확인
정확하게 맞은 개수를 확인
# 정답을 정확하게 맞춘 갯수
(y_train == y_valid_predict).sum()결과 : 10
전체 예측 해야되는 개수는?
# 전체 예측해야 하는 train 데이터의 갯수
(y_train == y_valid_predict).mean()0.1204819...
12%
분류모델보다 성능이 떨어진다.
=> 알 수 있는 점
regression모델은 분류지표로 사용하면 안된다.
4) 수치형 값을 시각화한다.
# regplot 으로 결과 값을 비교합니다.
sns.regplot(x=y_train, y=y_valid_predict)
y축 ----- 에 점들이 있으면 best인데, 많이 벗어난 상태.
# jointplot 으로 실제값과 예측값을 비교합니다.
sns.jointplot(x=y_train, y=y_valid_predict, kind="hex")
# residplot 으로 잔차(오차값)을 시각화 합니다.
sns.residplot(x=y_train, y=y_valid_predict)resid는 잔차이다.
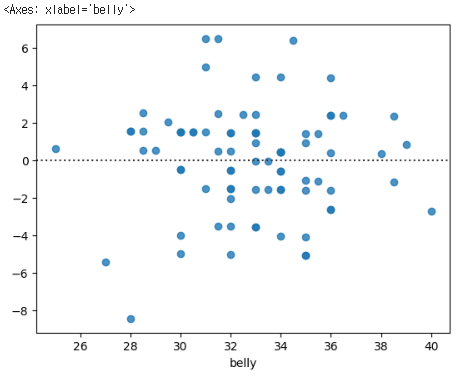
0 이 예측이 잘된 것이다. 지금 예측을 잘 못했기 때문에 많이 벗어나 있다.
---
5) R2Score 성능평가
회귀모델 성능을 평가하는 지표중 하나가 r2score이다.
결정계수라고도 부른다. 분산을 얼마나 잘 설명하는지 나타낸다. 0과 1사이의 값을 가진다.
결정계수(R² Score)란?
결정계수는 회귀 모델이 데이터의 분산을 얼마나 잘 설명하는지를 나타내는 지표다. 수치는 0과 1 사이의 값을 가진다. 이 값은 모델이 데이터의 변동성을 얼마나 잘 포착하고 있는지를 수치적으로 보여준다.
- 계산 방법
결정계수는 다음과 같은 공식으로 계산된다:

여기서:
- SSres는 잔차 제곱 합(Residual Sum of Squares)이다. 이는 실제 값과 모델에 의해 예측된 값 사이의 차이를 제곱한 값의 합이다.
- 는 총 제곱 합(Total Sum of Squares)이며, 실제 값과 실제 값의 평균과의 차이를 제곱한 값의 합이다.
해석
- R² = 1: 모델이 데이터 포인트를 완벽하게 예측, 데이터의 모든 변동성을 완벽하게 설명. 모든 데이터 포인터가 모델에 의해 예측된 선에 정확히 위치
- R² = 0: 모델이 데이터의 분산을 전혀 설명하지 못한다는 것을 의미한다. 이 경우 모델의 예측이 단순히 평균값으로 이루어진 것과 다름이 없다.
- R² < 0: 이례적인 경우로, 모델이 데이터의 평균보다도 더 나쁜 예측을 하는 경우 발생. 이는 모델이 데이터를 잘못 학습했거나 데이터 자체가 매우 잡음이 많은 경우일 수 있다.
# r2_score 를 구합니다.
from sklearn.metrics import r2_score
r2_score(y_train, y_valid_predict)
-1.0008036 ... 나오는데, 이것으로 해당 예측이 평균보다도 못하다는 걸 알 수 있다.
# y_train, y_predict 값을 데이터프레임으로 만듭니다.
df_y = pd.DataFrame({"y_train": y_train,
"y_valid_predict" : y_valid_predict})
df_y이 코드를 통해서, y_trian 과 y_predict 값을 데이터프레임으로 볼 수 있다. 차이가 많이 난다.
distplot으로 분포를 그릴 수도 있다.
# displot으로 정답값과 예측값의 분포를 그립니다.
sns.displot(df_y, kde=True, height=2, aspect=5)
오차구하기
# 오차 구하기
error = y_train - y_valid_predict
# 오차값에 대한 절대값의 describe 값을 구합니다.
abs(error).describe()
6) MAE (Mean Absolute Percentage Error)
위의 오차에 대한 절대값의 평균이 MAE이다.
# 예측값과 실제값의 차이에 대한 절대값의 평균
error = y_train - y_valid_predict
mae = abs(error).mean()
mae0에 가까울 수록 좋다.
7) MAPE(Mean Absolute Percentage Error)
# (실제값 - 예측값 / 실제값)의 절대값에 대한 평균
error = y_train - y_valid_predict
mape = abs(error/y_train).mean()
mapeMape는 오차/실제값의 절대값의 평균
8) MSE(Mean Square Error)
# 실제값 - 예측값의 차이의 제곱의 평균
# MAE와 비슷해 보이나 제곱을 통해 음수를 양수로 변환함
# 분산과 유사한 공식
error = y_train - y_valid_predict
mse = np.square(error).mean()
mseMse는 오차의 제곱값의 평균이다. (젤많이쓰임)
9) RMSE(Root Mean Squred Error)
# RMSE
rmse = np.sqrt(mse)
rmse이전에는 단순히 오차를 기반으로 모델의 예측 성능을 평가했지만, 이러한 지표들이 외부 요인이나 노이즈에 취약할 수 있다는 인식 하에 더 안정적인 모델 평가 방법이 개발되어왔다. RMSE가 노이즈에 제일 강인한 지표이다. 노이즈가 높다고 해서 값이 높아지지 않고,적절한 분산으로 적절한 분산을 뽑아준다.
10) 피처의 중요도 시각화하기
# 피처의 중요도 시각화 하기
sns.barplot(x=model.feature_importances_, y=feature_names, hue=feature_names)
11) 예측
# y_test
y_predict = model.predict(X_test)
y_predict[:5]
예측값과 실제값 비교하기
train.groupby("site")["belly"].describe()
개발자들 random_state 로 42를 많이 쓰는 이유...
[42(은하수를 여행하는 히치하이커를 위한 안내서)
더글러스 애덤스 의 은하수를 여행하는 히치하이커를 위한 안내서 에 나오는 삶, 우주 , 그리고 모든 것에 대한
개발자들이 42라는 숫자를 자주 사용하는 것은 문화적인 참조 때문입니다. 이 숫자는 더글러스 애덤스의 고전 소설 "은하수를 여행하는 히치하이커를 위한 안내서"에서 중요한 역할을 합니다. 소설에서 42는 "생명, 우주, 그리고 모든 것에 대한 궁극적인 질문의 답"으로 제시됩니다. 이러한 유머러스한 설정 때문에, 많은 과학 기술 관련 커뮤니티에서 42는 재미있고 상징적인 숫자로 받아들여지며, 일종의 내부 농담처럼 사용되곤 합니다. 이는 코드 내에서 작은 오마주나 이스터 에그처럼 작용할 수 있습니다.
=> 재미로 읽어볼것.....개발자의 유우머....랜다...